


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Asahi, Yuichi; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Dai-36-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 8 Pages, 2022/12
We implement a kinetic plasma simulation code with multiple performance portable frameworks and evaluated its performance on Intel Icelake, NVIDIA V100 and A100 GPUs, and AMD MI100 GPU. Relying on the language standard parallelism stdpar and proposed language standard multi-dimensional array support mdspan, we demonstrate a performance portable implementation without harming the readability and productivity. With stdpar, we obtain a good overall performance for a kinetic plasma mini-application in the range of 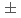 20% to the Kokkos version on Icelake, V100, A100 and MI100. We conclude that stdpar can be a good candidate to develop a performance portable and productive code targeting Exascale era platforms, assuming this programming model will be available on AMD and/or Intel GPUs in the future.
20% to the Kokkos version on Icelake, V100, A100 and MI100. We conclude that stdpar can be a good candidate to develop a performance portable and productive code targeting Exascale era platforms, assuming this programming model will be available on AMD and/or Intel GPUs in the future.
Asahi, Yuichi; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
Times Cited Count:0 Percentile:0(Computer Science, Theory & Methods)This paper presents the performance portable implementation of a kinetic plasma simulation code with C++ parallel algorithm to run across multiple CPUs and GPUs. Relying on the language standard parallelism stdpar and proposed language standard multi-dimensional array support mdspan, we demonstrate that a performance portable implementation is possible without harming the readability and productivity. We obtain a good overall performance for a mini-application in the range of 20% to the Kokkos version on Intel Icelake, NVIDIA V100, and A100 GPUs. Our conclusion is that stdpar can be a good candidate to develop a performance portable and productive code targeting the Exascale era platform, assuming this approach will be available on AMD and/or Intel GPUs in the future.
Asahi, Yuichi; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of 2021 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.79 - 91, 2021/11
This paper presents optimization strategies dedicated to a kinetic plasma simulation code that makes use of OpenACC/OpenMP directives and Kokkos performance portable framework to run across multiple CPUs and GPUs. We evaluate the impacts of optimizations on multiple hardware platforms: Intel Xeon Skylake, Fujitsu Arm A64FX, and Nvidia Tesla P100 and V100. After the optimizations, the OpenACC/OpenMP version achieved the acceleration of 1.07 to 1.39. The Kokkos version in turn achieved the acceleration of 1.00 to 1.33. Since the impact of optimizations under multiple combinations of kernels, devices and parallel implementations is demonstrated, this paper provides a widely available approach to accelerate a code keeping the performance portability. To achieve an excellent performance on both CPUs and GPUs, Kokkos could be a reasonable choice which offers more flexibility to manage multiple data and loop structures with a single codebase.
Asahi, Yuichi; Latu, G.*; Bigot, J.*; Grandgirard, V.*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.218 - 224, 2020/10
Performance portability is expected to be a critical issue in the upcoming exascale era. We explore a performance portable approach for a fusion plasma turbulence simulation code employing the kinetic model, namely the GYSELA code. For this purpose, we extract the key features of GYSELA such as the high dimensionality (more than 4D) and the semi-Lagrangian scheme, and encapsulate them into a mini-application which solves the similar but a simplified Vlasov-Poisson system as GYSELA. We implement the mini-app with OpenACC, OpenMP4.5 and Kokkos, where we suppress unnecessary duplications of code lines. Based on our experience, we discuss the advantages and disadvantages of OpenACC, OpenMP4.5 and Kokkos, from the view point of performance portability, readability and productivity.
Uno, Sadanori; Tajima, Satoshi; ; Mizuhashi, Kiyoshi; ; Sasuga, Tsuneo; *; *
Dai-7-Kai Tandemu Kasokuki Oyobi Sono Shuhen Gijutsu No Kenkyukai Hokokushu, 0, 4 Pages, 1994/00
no abstracts in English
Watanabe, Tadashi; Kukita, Yutaka
Numerical Modelling of Basic Heat Transfer Phenomena in Nuclear Systems, p.25 - 30, 1991/00
no abstracts in English
;
JAERI-M 5657, 49 Pages, 1974/04
no abstracts in English
Asahi, Yuichi; Maeyama, Shinya*; Latu, G.*; Garbet, X.*; Watanabe, Tomohiko*; Aoki, Takayuki*; Ogino, Masao*
no journal, ,
Under the JHPCN international collaboration with French researchers, we have integrated a kinetic electron model into the kinetic plasma turbulence code GYSELA developed in France. We also explore a performance portable for a kinetic fusion plasma turbulence code like GYSELA. For this purpose, we extract the key features of GYSELA such as the high dimensionality and the semi-Lagrangian scheme, and encapsulate them into a mini-application which solves the simpler version of Vlasov-Poisson system as GYSELA. We implement the mini-app with Open ACC and Kokkos to evaluate the advantages and disadvantages of each approach, from the view point of performance portability, readability and productivity.
Asahi, Yuichi; Latu, G.*; Bigot, J.*; Grandgirard, V.*
no journal, ,
To prepare the performance portable version of the kinetic plasma simulation code, we develop a simplified but self-contained semi-Lagrangian mini-app with Kokkos performance portable framework and OpenMP/OpenACC which works on both CPUs and GPUs. We investigate the performance of the mini-app over the novel arm-based processor Fujitsu A64FX, Nvidia Tesla GPU, and Intel Skylake, where the arm-based architectures and GPUs are supposed to be major architectures in the exa-scale supercomputing era. The porting cost is highly suppressed with both Kokkos and directive implementations, where the code duplication is avoided. The higher performance portability is achieved with OpenMP/OpenACC, particularly for the compute intense kernels among the hotspots. Unfortunately, a relatively low performance is obtained on A64FX for kernels with indirect memory accesses. We also discuss what kind of Kokkos/OpenMP/OpenACC features are useful to improve the readability and productivity.
Asahi, Yuichi
no journal, ,
We present optimization strategies dedicated to a kinetic plasma simulation code that makes use of OpenACC/OpenMP4.5/OpenMP directives and Kokkos performance portable framework to run across multiple CPUs and GPUs. We evaluate the impacts of optimizations on multiple hardware platforms: Intel Xeon Skylake, and Nvidia Tesla P100 and V100. After the optimizations, the OpenACC/OpenMP version achieved the acceleration of 1.07 to 1.39. The Kokkos version in turn achieved the acceleration of 1.00 to 1.33. Since the impact of optimizations under multiple combinations of kernels, devices and parallel implementations is demonstrated, this paper provides a widely available approach to accelerate a code keeping the performance portability. To achieve an excellent performance on both CPUs and GPUs, Kokkos could be a reasonable choice which offers more flexibility to manage multiple data and loop structures with a single codebase.
Asahi, Yuichi; Hasegawa, Yuta; Padioleau, T.*; Millan, A.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
no journal, ,
Generally, production-ready scientific simulations consist of many different tasks including computations, communications and file I/O. Compared to the accelerated computations with GPUs, communications and file I/O would be slower which can be major bottlenecks. It is thus quite important to manage these tasks concurrently to suppress these costs. In the present talk, we employ the proposed language standard C++ senders/receivers to mask the costs of communications and file I/O. As a case study, we implement a 2D turbulence simulation code with the local ensemble transform Kalman filter (LETKF) using C++ senders/receivers. In LETKF, the mock observation data are read from files followed by MPI communications and dense matrix operations on GPUs. We demonstrate the performance portable implementation with this framework, while exploiting the performance gain with the introduced concurrency.

